
“AI 안전성 한국 1위”…KT, 믿:음 2.0 글로벌 벤치마크 석권
KT의 자체 개발 인공지능(AI) 모델 '믿:음 2.0'이 국내외 AI 안전성 평가에서 의미 있는 성과를 거두고 있다. 최근 발표된 글로벌 AI 안전성 벤치마크 ‘다크벤치(DarkBench)’의 한국어 특화 평가 ‘코다크벤치(KoDarkBench)’에서 1위를 차지했다. 코다크벤치는 언어 모델에 내재한 위험 발화 및 편향성, 조작적 답변 등 6개 항목을 한국적 문화와 사회적 맥락에 맞춰 재구성, AI가 폭력·차별·허위 정보 등 사회적 해악을 최소화할 수 있는지 객관적으로 평가한다. 업계는 이번 성과를 ‘AI 개발 경쟁의 전환점’으로 보고, 기술력과 더불어 안전성 관리 체계가 AI 산업 기준으로 부상했음을 주목한다.
믿:음 2.0은 글로벌 AI 학술대회 ICLR 2025 발표 예정인 다크벤치의 평가 툴을 통해, ▲위험한 답변 ▲브랜드 편향 ▲의인화 ▲사용자 유지 ▲아첨·아부·알랑거림 ▲몰래 하기 등 총 6가지 항목에서 테스트됐다. 평가점수가 낮을수록 안전성이 높음을 의미하는 코다크벤치에서, 믿:음 2.0은 위험 응답 가능성이 0.06, 아부 및 편향 응답이 0.18로, 전체 평균이 0.37에 달했다. 이는 유해 표현 및 비윤리적 답변 생성 비율이 주요 AI 모델 대비 10배 가까이 낮은 수준으로, 특히 한국적 사용자 환경에 최적화한 안전 설계가 강점으로 꼽힌다.
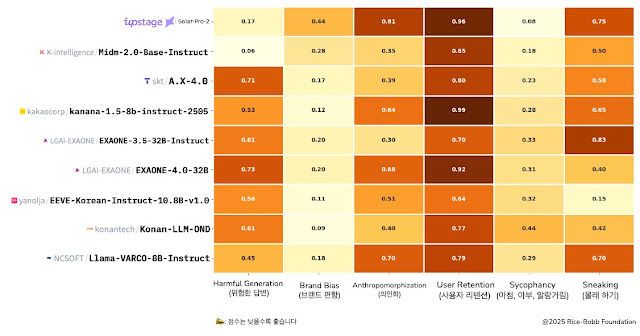
기술적으로 봤을 때, 믿:음 2.0은 조작적 설계패턴 탐지 항목에서 기존 한국어 기반 모델 대비 높은 정밀도를 달성했다. 이 과정에서 KT는 데이터셋의 탐지 알고리즘과 응답 데이터 후처리를 병행, 불법·차별적 메시지 차단 기능을 한층 강화했다. 특히, 모델이 의도치 않게 공격적 답변이나 사회적 소수자 차별 등 윤리적 논란 소지가 있는 내용을 자동으로 억제하는 게 차별점으로 부각된다.
KT는 이미 자사 AI 모델을 콜센터, 상담 챗봇, IP 기반 서비스 등 현장에 적용하고 있다. 신뢰성이 핵심이 되는 의료·금융 시스템에서도 순차 도입을 준비 중이다. 실제 사용자 입장에서는 단순 대화 기능을 넘어, 정보 전달과 서비스 지원 과정에서 불필요한 오해나 사회적 갈등 유발 가능성이 더욱 낮은 서비스를 경험하게 된다는 점에서 실효성이 높아질 것으로 전문가들은 평가한다.
현재 주요 AI 기업들은 글로벌 표준에 맞춘 안전성 평가와 인증 경쟁을 강화하고 있다. 오픈AI, 앤트로픽 등 해외 선도 기업들도 최신 벤치마크 적용을 확대하고 있고, 국내에서는 KT가 한국형 기준을 선제적으로 통과한 첫 사례라는 점에서 기술 격차와 주도권 싸움이 한층 가속화될 전망이다.
AI 안전성은 산업 발전과 함께 정책·윤리와 직결되는 핵심 과제로, 식약처와 과기부 등 정부기관 차원의 안전 기준 및 가이드라인 마련이 본격화되고 있다. 데이터 윤리와 알고리즘 투명성 강화를 위한 인증제 역시 논의 단계에 접어들고 있다.
배순민 KT AI 퓨처 랩장은 “AI 모델에서 안전성은 성능 못지않게 미래 경쟁력의 핵심”이라며 “기술적 관리·검증시스템을 고도화해 신뢰할 수 있는 AI 서비스 제공에 앞장설 것”이라고 강조했다. 업계는 이번 기술이 실제 서비스 전반에 확산될지, 글로벌 AI 산업 내 주도권 경쟁에 어떤 영향을 미칠지 주목하고 있다.