
“한국적 LLM 믿:음 2.0 오픈”…KT, MS AI 협업과 투트랙 선언
한국형 인공지능 ‘믿:음 2.0’이 오픈소스 기반으로 공개되며 IT·바이오 산업 내 데이터 주권 경쟁과 AI 생태계 독립성 강화를 예고하고 있다. KT가 마이크로소프트(MS)와의 협업을 병행하면서도 독자 개발 LLM(대규모 언어모델)을 포기하지 않겠다는 방침을 공식화함에 따라, 국내 AI 플랫폼 주도권 경쟁이 본격화되는 분위기다. 업계는 이번 발표가 외산 AI 의존 탈피 및 ‘소버린AI’ 확산 경쟁의 분기점이 될 수 있다고 해석하고 있다.
KT는 4일부터 자체 개발 LLM ‘믿:음 2.0’을 AI 개발자 플랫폼 허깅페이스에 오픈소스로 제공한다. 115억 매개변수 규모의 ‘믿:음 2.0 베이스’와 23억 파라미터 ‘미니’ 2종 모두 한국어·영어를 지원하며, 상업적 활용 제한도 없다. 신동훈 KT 젠AI 랩장은 “모델 데이터 구축부터 학습까지 전 과정을 자사 원천 기술로 구현했고, 사용자의 데이터가 해외로 유출되지 않도록 보장한다”며, “소버린AI(주권 AI) 원칙을 지키는 대표적 모델로 자리매김할 것”이라고 강조했다.
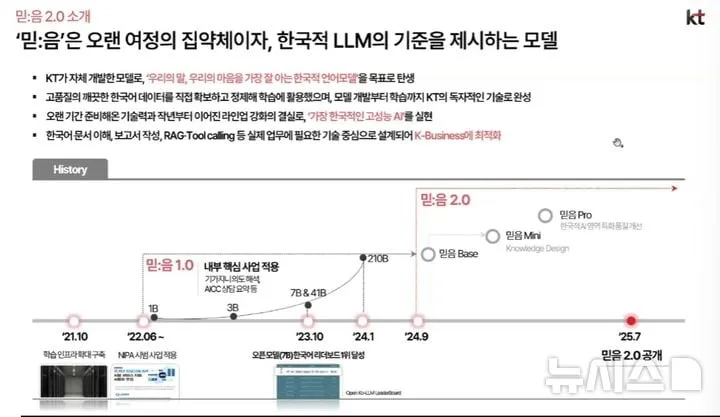
기술적으로 ‘믿:음 2.0’은 한국 사회적 맥락과 언어문화 특수성을 모델링해, GPT 등 범용 영어 LLM과 차별화된 한국형 AI 성능을 목표로 한다. KT는 대규모 파라미터, 로컬 학습, 언어별 최적화 등이 특징이라고 소개했다. 특히 데이터 흐름의 국지화를 통해 개인정보 보호와 서비스 안정성을 확보할 수 있다는 점이 핵심이다. 추후 프로, 추론 특화, 멀티모달 등 라인업 확장도 예고됐다.
실제 시장에서 KT는 MS와의 협업 LLM(GPT 기반 플랫폼) 그리고 자체 ‘믿:음’ LLM을 양날개로 운용하는 병행 전략을 밝히고 있다. 고객이 작업 난이도와 데이터 조건에 따라 맞춤 선택할 수 있는 ‘모델 포트폴리오’를 제시하는 구조다. “외국계 주요 AI가 불가능한 환경, 혹은 데이터 보호 요구가 높은 경우 믿:음 2.0이 대안이 될 수 있다”고 KT는 설명했다.
국내외 경쟁구도 측면에서 KT는 “믿:음은 데이터얼라이언스와 함께 처음부터 직접 구축한 완전 독자 모델”이라고 선을 그었다. SK텔레콤 ‘A.X 4.0’ 등이 오픈소스 ‘큐엔(Qwen)2.5’에 한국어 추가 학습하는 하이브리드 방식인 것과 달리, KT는 개발-학습-서비스 전 과정을 독자 수행하고 있다. 이에 따라, 국가·공공 영역 등 데이터 주권 요구가 높은 분야에서 경쟁력이 부각될 가능성도 있다.
이번 발표는 정부의 파운데이션 모델 프로젝트 참여, 규제 완화 요구와도 맞물린다. 신 랩장은 “공공 데이터에는 법적으로 문제 없는 경우조차 규제상 AI 학습에 활용하지 못하는 제약이 있다”며 “국가가 통제하는 고품질 데이터를 적극 개방해야 한다”고 언급했다. AI 소프트웨어 산학협력, 국내 데이터 보호 강화, 글로벌 AI 자율 규제 동향 대비 등이 제도 차원 논의과제로 부상했다.
전문가들은 KT를 비롯한 기업들이 자체 원천 LLM을 확보하는 것이 글로벌 AI 주도권 경쟁, 산업 데이터 자립성, 윤리적 AI 생태계 기반에 점점 더 중요해지고 있다고 본다. “AI 기술력뿐 아니라, 데이터 국적·활용 방식의 차이가 산업 생태계 전반에 지각변동을 가져올 수 있다”는 지적이다. 산업계는 이번 기술 공개가 실제 시장에 안착할 수 있을지 예의주시하고 있다.