

“AI가 소실점까지 읽는다”…UNIST, 자율주행 카메라 인식 혁신
원근법의 핵심 개념인 ‘소실점’을 인공지능 알고리즘에 적용해 자율주행차의 카메라 인식 정확도가 한 단계 높아졌다. 울산과학기술원(UNIST) 인공지능대학원 주경돈 교수팀은 15일 카메라 영상의 원근 왜곡 문제를 극적으로 보완하는 AI 모델 ‘VPOcc’를 개발했다고 발표했다. 해당 기술은 르네상스 회화의 원근법 기법과 딥러닝 시스템을 결합, 카메라 기반 자율주행차 및 로봇 환경 인식의 패러다임을 전환할 신기술로 주목받고 있다.
VPOcc는 카메라에 입력된 2차원 영상정보에서 소실점(Parallel-line vanishing point)을 기준축 삼아, 거리 및 깊이 표현의 왜곡을 정확히 보정한다. 소실점은 멀리서 평행하게 뻗은 차선, 철도 레일 등이 하나로 모여드는 지점으로, UNIST 연구팀은 평면 영상에 깊이감을 재구성하는 인공지능 모듈을 개발해 이미지 속 객체의 실제 거리와 형태를 더욱 정밀하게 복원하도록 설계했다.
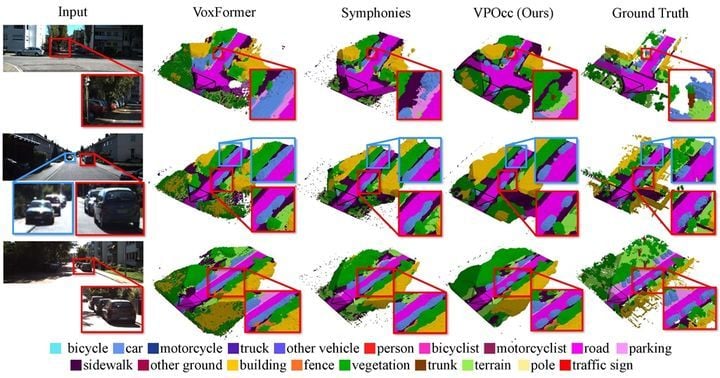
새 모델은 크게 세 부분으로 구성된다. VPZoomer는 소실점에 따라 자료를 재배열해 원근 왜곡을 최소화하며, VPCA는 멀고 가까운 영역의 정보 수집을 균형 있게 한다. 마지막 SVF 모듈은 원본과 보정 이미지의 정보를 통합, 전반적인 인식 성능을 최대화했다. 실험 결과 VPOcc는 기존 벤치마크 대비 공간 이해 지표(mIoU)·복원 정확도(IoU) 모두 탁월한 수치를 기록했고, 특히 자율주행차에서 중요한 도로상의 먼 사물과 겹친 객체들을 기존 방식보다 선명하고 명확하게 판별했다.
이 연구에는 김준수 UNIST 연구원이 제1저자로 참여하고, 이준희 연구원 및 미국 카네기멜론대학교와 협업이 이뤄졌다. 주경돈 교수는 “이번 AI 모델은 로봇, 자율주행, 증강현실(AR) 지도 제작 등 실물 산업의 다양한 현장에서 활용될 수 있을 것”이라고 설명했다.
해외에서는 라이다(LiDAR) 센서 기반 인식도 병행된다. 그러나 카메라는 가격과 장착 편의성, 색·형태 정보 제공 등에서 우위를 보여 첨단 자율주행차와 로봇 플랫폼에서 핵심 위치를 차지하고 있다. 글로벌 시장에서는 머신비전 AI와 원근 왜곡 해결 기술 경쟁이 가속화되는 추세다.
이번 연구는 과학기술정보통신부와 한국연구재단 지원으로 수행됐으며, 성과는 삼성휴먼테크논문대상 은상에 선정됐고, 국제 로봇자동화 학회(IROS) 2025 논문에도 채택됐다. 전문가들은 “원근법 AI 융합 기술이 실제 자율주행 및 로봇 산업의 실전 적용 시, 인공지능 기반 공간 인식의 질적 도약을 이끌 계기가 될 수 있다”고 평가한다. 산업계는 이번 기술이 현장에 조기 안착할 수 있을지 예의주시하고 있다.