
“KT, 독자 AI 믿:음 2.0 오픈”…MS와 양날개 전략 시동
KT가 자체 개발한 한국형 인공지능(AI) ‘믿:음(믿음) 2.0’을 오픈소스로 공식 공개하며, 마이크로소프트(MS)와의 협력을 통한 글로벌 AI 기술과의 ‘양날개 전략’을 본격화했다. KT는 4일부터 AI 개발자 플랫폼 허깅페이스를 통해 믿:음 2.0 전체 모델을 소스와 함께 공개, 누구나 자유롭게 상업적·비상업적 목적에 활용할 수 있도록 했다. 업계에서는 이번 전략을 ‘국내 AI 주권 수호와 글로벌 기술 경쟁력 확보’의 분기점으로 평가하고 있다.
KT가 2023년 선보인 믿:음 1.0에서 한 단계 진화한 이번 2.0 버전은 115억 파라미터 규모의 ‘베이스’ 모델과 23억 파라미터 ‘미니’ 모델 두 가지로, 한국어와 영어를 모두 지원한다. 모든 학습 단계와 데이터 구축 과정을 자체 기술로 개발한 것이 특징이다. 특히 사용자 데이터가 국외로 반출되지 않고 국내에 남게끔 해 데이터 주권을 지키는 ‘소버린AI(국가 주권형 AI)’ 원칙을 전면에 내세운다.
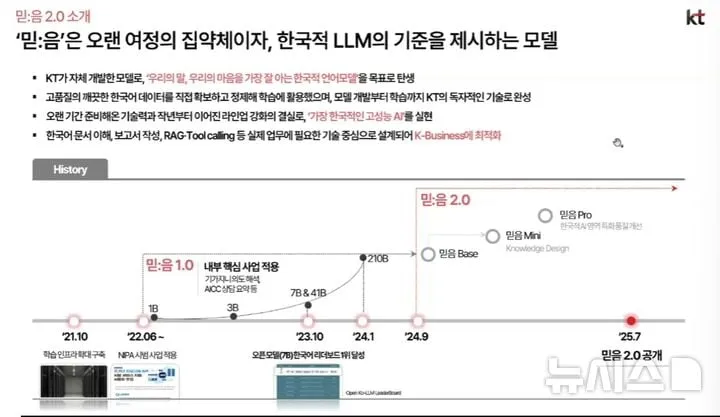
기술적으로는 자체 한국어 대규모 데이터셋과 한국적 사회문화를 반영한 학습설계가 차별점이다. KT는 모델의 경량화와 고성능을 모두 겨냥해 향후 프로 모델, 멀티모달 형태까지 단계별로 확대를 예고했다. 기존 글로벌 AI 모델의 일방적 도입이 아닌, 국내 특화된 최적화와 독립성을 강화했다는 평가를 받는다.
KT는 이와 별도로 MS와의 협업을 통해 챗GPT 기반의 차세대 한국형 AI 서비스도 추진 중이라고 밝혔다. 두 모델의 병행 전략에 따라, 각 기업 및 기관은 작업 목적이나 활용 환경에 따라 적합한 모델을 선택할 수 있다. 특히 대화·요약 등 일부 작업에는 고성능 글로벌 모델이, 공공·내부 데이터 활용 등에는 믿음과 같은 소버린AI가 강점을 보일 수 있다는 설명이다. KT는 “통신 인프라 기반 국민데이터의 해외 유출을 막고, 다양한 산업 현장에서 데이터 주권을 실현할 것”이라고 강조했다.
국내 경쟁구도도 격화된다. KT는 100% 자체 설계와 데이터로 구축한 점을 강조한 반면, 최근 SK텔레콤이 공개한 ‘A.X 4.0’ 모델은 중국 오픈소스 기반에 한국어 데이터만 추가돼 “출발점부터 다르다”는 입장을 밝혔다. A.X 4.0의 표준 모델이 720억 매개변수를 갖췄으나, KT 모델은 경량화와 실효적 적용을 우선했다.
AI 산업 규제 및 데이터법과 관련해, KT는 “공공 데이터 등 우수 품질의 데이터 세트가 현행 규제로 인해 AI 학습에 폭넓게 사용되지 못하고 있다”며 제도 개선의 필요성도 피력했다. 업계 전문가들은 “한국형 AI 모델이 지속적으로 고도화될 경우, 글로벌 경쟁 속에서 데이터 주권 확보와 산업 내 활용이 가속화될 수 있다”고 내다보고 있다.
산업계는 이번 KT의 독자 AI 확대와 MS 협력의 동시 행보가 데이터 주권과 혁신 경쟁력 사이에서 새로운 균형점을 제시할지 주시하고 있다. 기술의 진화와 제도적 뒷받침이 맞물리며 국내 AI 생태계의 본격적인 성장기로 이어질지 관심이 집중된다.